

《三维菁彩声(Audio Vivid)技术白皮书》解读:让音符在多维空间律动
戴上耳机,就能感受到“把环绕式音响装进耳朵里”的沉浸式体验。在不久前的2022总台秋晚上,三维菁彩声给我们带来了“声”临其境的震撼。
那么,这是如何做到的呢?又为何需要自主研发标准?近日,由中央广播电视总台、华为、当虹科技等单位联合起草,世界超高清视频产业联盟正式发布的《三维菁彩声(Audio Vivid)技术白皮书》给出了答案。
自研三维声标准:解决超高清音视频“卡脖子”难题
三维声是超高清视频“六维技术”的重要组成部分,可以带来空间感、方位感和临场感,让人感觉声音从“四面八方”“扑面而来”,带来非常“真实”和“沉浸”的体验。
然而,我国的三维声技术积累相对较少。国际主流的三维声技术方案,长期以来均由国外企业或标准组织制定。三维菁彩声的推出和应用,摆脱了超高清音视频关键技术“卡脖子”难题。
该标准由世界超高清视频产业联盟(UWA)牵头,与AVS编解码标准协同,联合产业“端到端”生态共同发布。这有利于快速推动超高清产业发展,提升超高清视频核心技关键技术标准影响力。
《白皮书》表示,Audio Vivid 技术标准的目标是一个面向全球,技术先进,更加开放的、具备产业安全要求的技术标准和方案,同时产业生态政策友好,更加适合超高清产业生态各方进行“端到端”的产业部署。2022总台中秋晚会,是对三维菁彩声技术的首次示范应用。
编解码+渲染:让音符在多维空间律动
相对传统声音,三维声增加了空间感和方位感,使听众能再现在现实世界中所听到的声音,从而满足人们对声音高度还原、高度沉浸的体验需求,同时可具备个性化选择和交互体验。

图1|Audio Vivid体验场景
三维菁彩声解决声音从构建到还原的整个环节,可以在家庭环境、影院环境、演唱会、体育赛事、个人、AR/VR 以及车载等多元场景中得以应用。
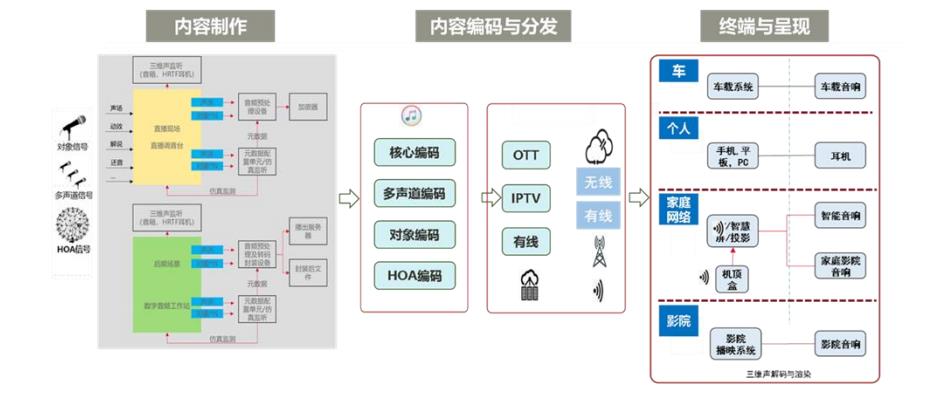
图2|Audio Vivid 集成场景
《白皮书》显示,三维菁彩声的编解码和渲染非常重要。尤其编解码,针对不同的信号类型采用不同的技术工具对输入信号进行编解码,解决了很多“信息冗余”的问题。比如,采用多声道编码技术,去除多声道信号间的信息冗余;用基于心理声学模型的预处理和基于 AI 的量化、熵编码技术,去除单声道、对象音频信号中的信息冗余。这都为最终渲染出“声”临其境的体验提供保障。
三维菁彩声还是全球首个基于AI技术的音频编解码标准,支持主流三维声编码的同时,兼容单声道、立体声、环绕声、三维声,可以让声音在三维空间的任何位置精准放置和移动,准确描述每一个声音的位置、大小、轨迹、时间、长度。戴上耳机,瞬间感受到音符在多维空间里的律动,与声音共鸣的,将是大脑而不是耳朵。
在各方的联合支持下,三维菁彩声技术标准已经完成了“端到端”的体系建设,并逐渐进入落地应用阶段。例如,在核心的编解码阶段,当虹科技的8K超高清编解码技术已支持三维菁彩声,联合产业链上下游企业,可以为人们提供纤毫毕现、“声”临其境的体验。
 扫码领资料
扫码领资料
 扫码看视频
扫码看视频